Real Time Medical Device Vital Signs Prediction Using Kafka and Spark (Part 1)
This is the first part of our near-real-time vital signs predicting & alerting application. We will be simulating streaming vital sign data from medical devices using Apache Kafka. The streaming data can then be used to develop a near-real-time alerting and prediction by applying machine learning algorithms from Spark's mlib package. This can help predict when an adverse event might occur for a patient. Real-time streaming data is essential the when monitoring patients that are in critical conditions. You can imagine that the sensors and physiological monitors help paint the picture of the current state of the patient. We can use machine learning to help with our clinical decision in real-time when it matters most to the patient’s health. You can find the code to this project here find the code here on github
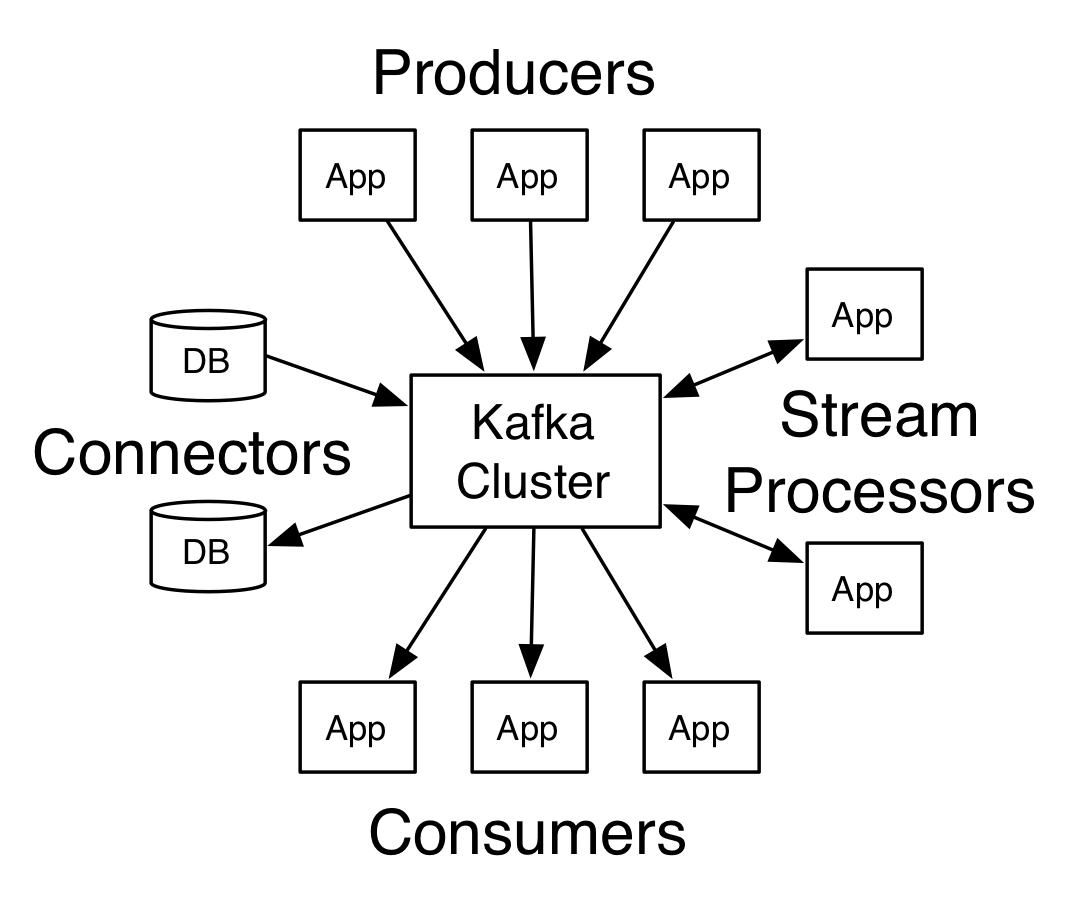
In this post, we will focus on building a Kafka producer to simulate vitals data from a patient. We will simulate real-time data from various medical devices during the case such as cardiac monitors, pulse oximeters, physiological monitors, and non-invasive blood pressure cuff. The simulated medical devices will publish data to a Kafka broker and can be consumed by our Spark application or Kafka consumer. Later on, I want to use historical patient data and combine it with real-time data to improve the prediction of the system and make it more personalized for the patient. This might consider family history, genetic information, drug history, and past health events. This can take us one step closer to personalized medicine where decisions are made by taking into account the patient’s current and past state.
Introduction to Apache Kafka
Kafka is a distributed publish subscribe messaging system created by LinkedIn. It is scalable and it can handle high throughput messaging. We are talking > 1million messages/sec! The basic principle of a pub/sub system is that you have producers that publishes data to centralized data brokers for a specific topic then consumer applications can read messages for the topics they are subscribed to. You can read more about the basics here.
Kafka can handle messages from different sources at an extremely fast rate, perfect for streaming vital signs data from medical devices. A central data broker allows various medical devices to publish data so a consuming application only needs to subscribe to the topics it is interested in. For example, an application can subscribe to a topic called “Cardiac Monitor” to get data from just the cardiac monitor or you can subscribe to a topic called “Vitals” to get data from 5 various monitors for a specific patient. Additionally, consuming applications don’t need to manage the connections for every producer because data is sent to the centralized data brokers. You can easily add and remove producers in your system. Kafka can persist data for a set period typical for 7 days. If consumers are consuming at different rates there won't be any data loss or missed messages. Each consumer is independent of each other and is responsible for keeping track of what position they are at in the data stream. Kafka makes this possible because the messages are appended to a commit log and are immutable. So, every message is stored and has a unique number which determines its order.
Project Dependencies
Pom File
We need to include a few dependences in our POM file. The Kafka library will give us access to the producer and consumer classes. Additionally we will use the shade plugin to create an uber jar so we can independently execute the jar file. The jackson-databind will be used to serialize and deserialize json messages.
Steps to Deploy Locally on Windows
Start a Zookeeper Server
Start a Zookeeper Server
Start zookeepr server by typing zkserver in the command line. You can define the server parameters in the config file For this demo app run zookeeper locally on port 2181. The zookeeper server is used to manage the work for the Kafka brokers
Start a Kafka broker
Start zookeepr server by typing zkserver in the command line. For this demo app run zookeeper locally on port 2181. The zookeeper server is used to manage the work for the Kafka brokers
Create a Kafka Topic
Create topic kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic vitals. This command defines the partitions and the connection to our Zookeeper server. In this case we will be running on port 9092. the partitions acts as parallelisms to increase operational efficiency. This allows for multiple threads to be created to handle a large amount of consuming applications to read from the topics.
Create a Kafka Consumer and Vital Signs Producer
Execute your jar and pass the parameters
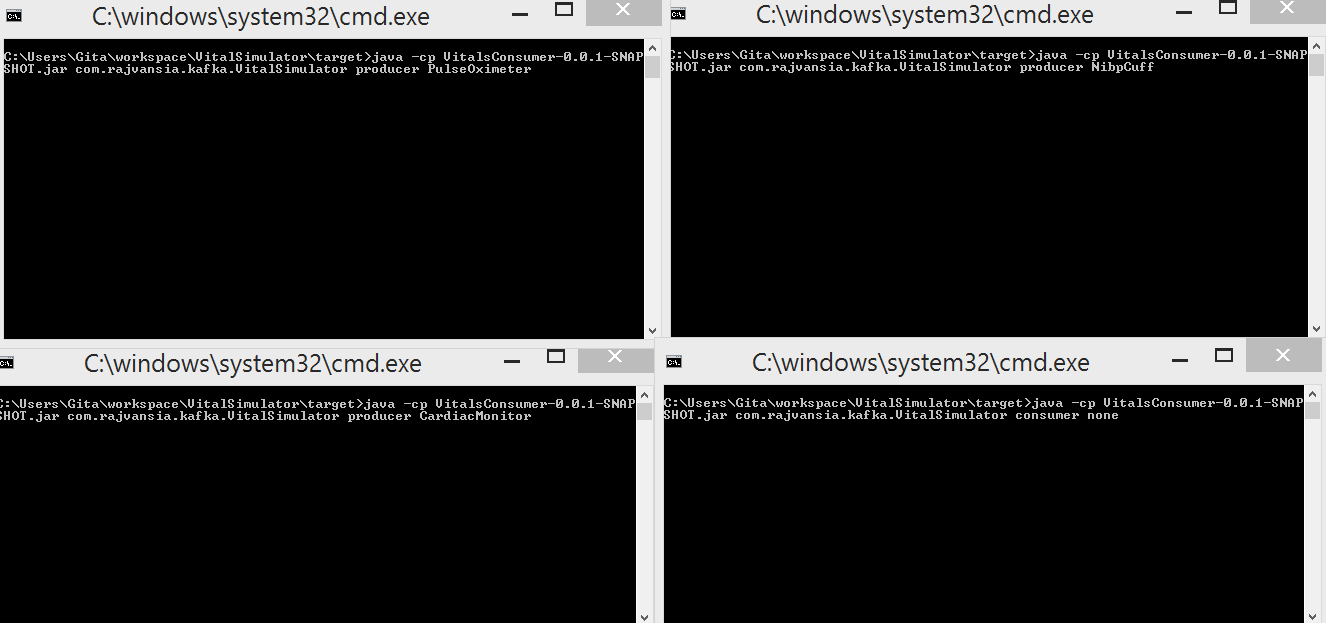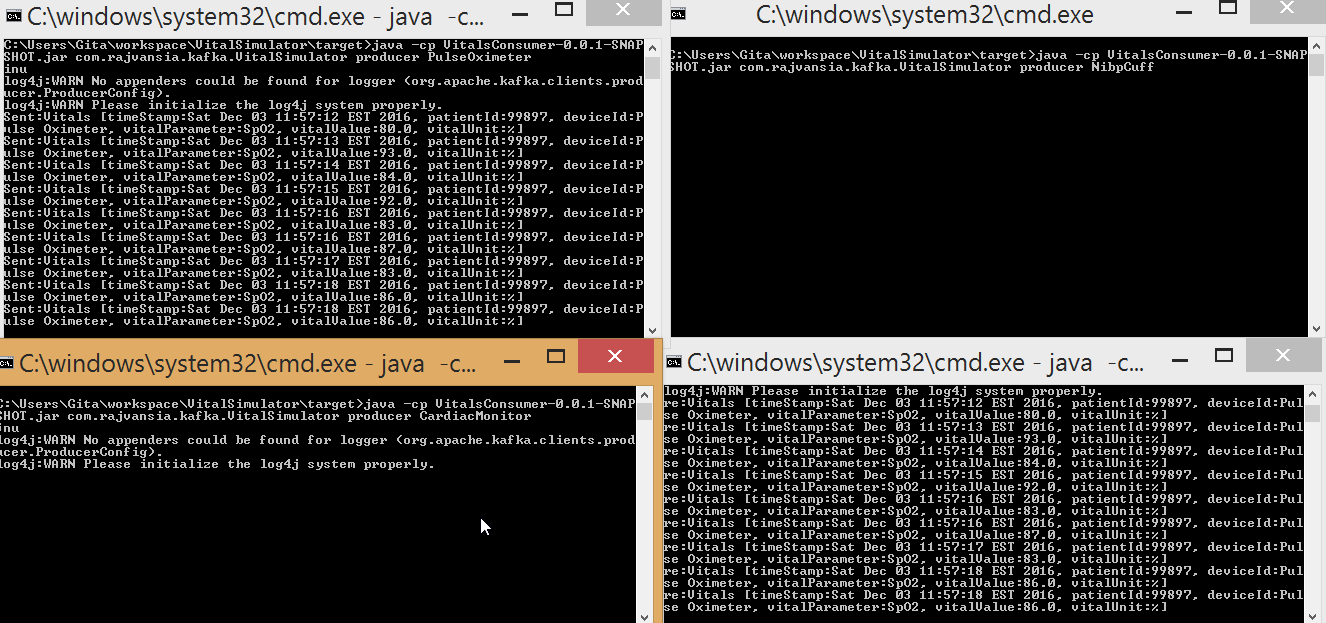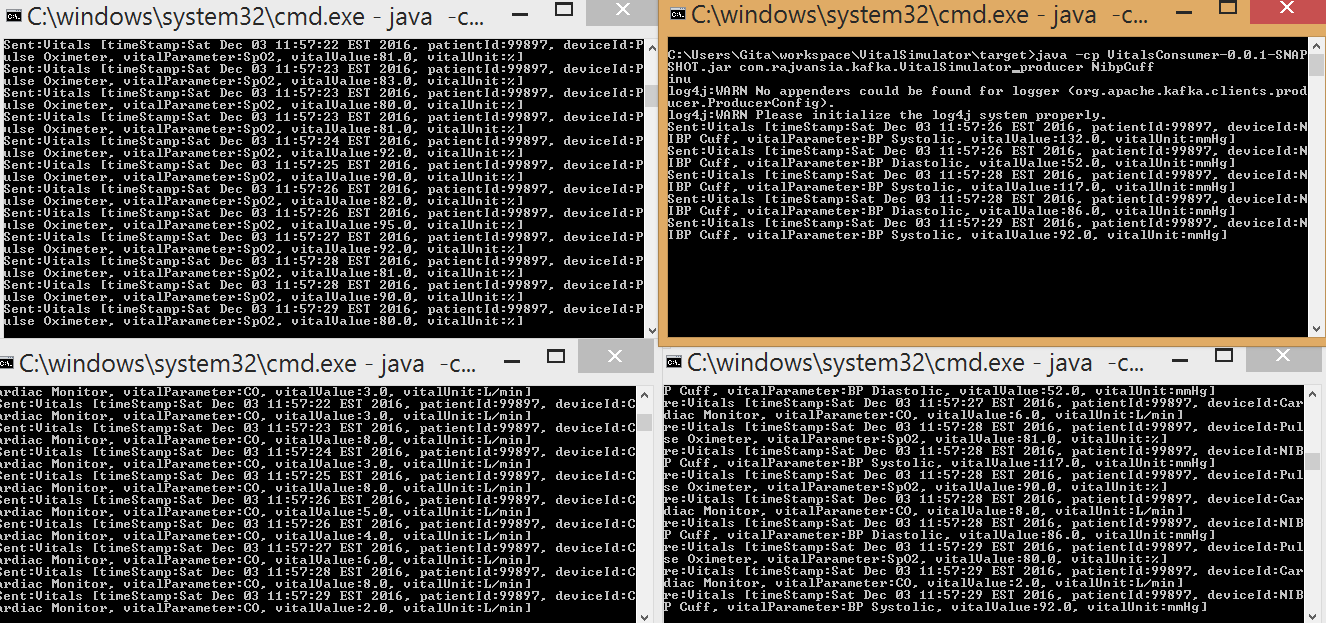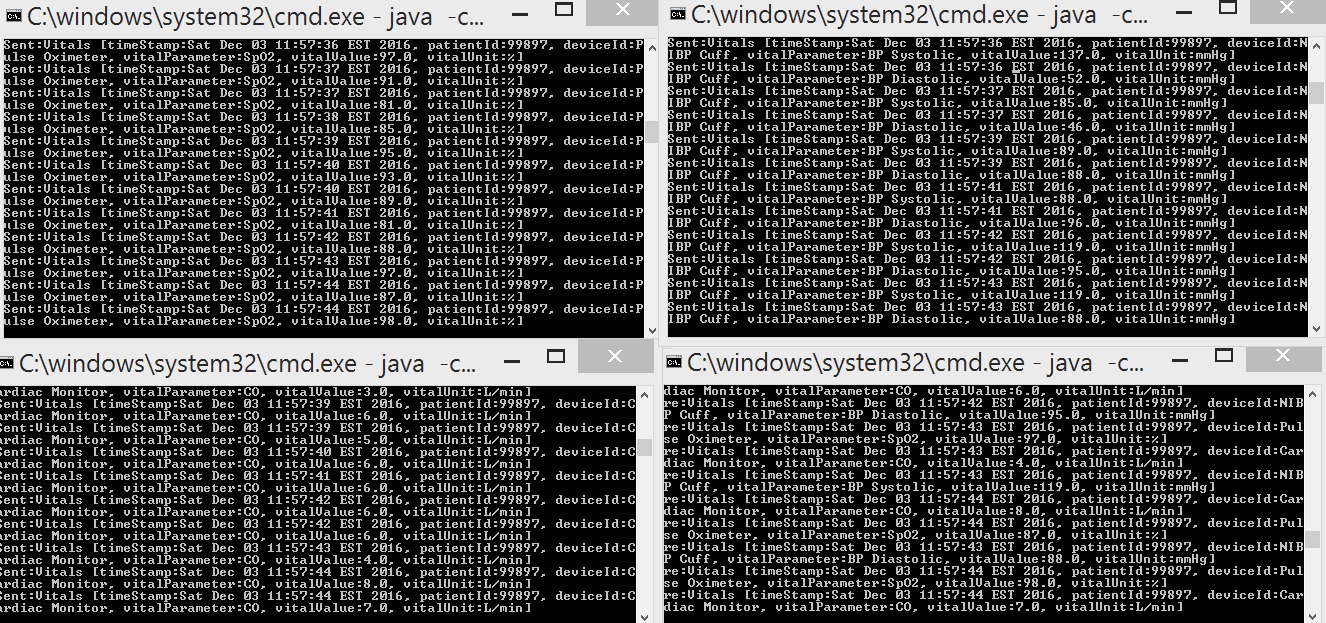
To create the producer app execute the jar file by accessing the main VitalSimulator class and pass the parameters of the device type "producer device type". For example if we want to simulate a cardiac monitor we will pass producer CardiacMonitor. The producer will produce simulated data to the Kafka broker then the consumers can subscribe to that topic and retrieve those messages.
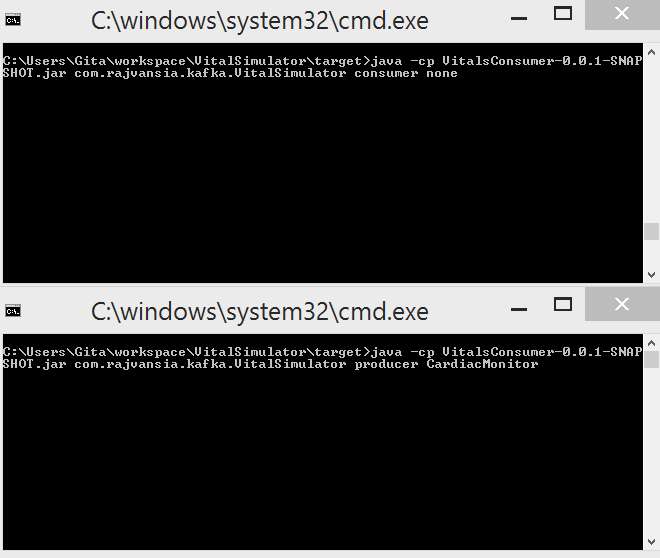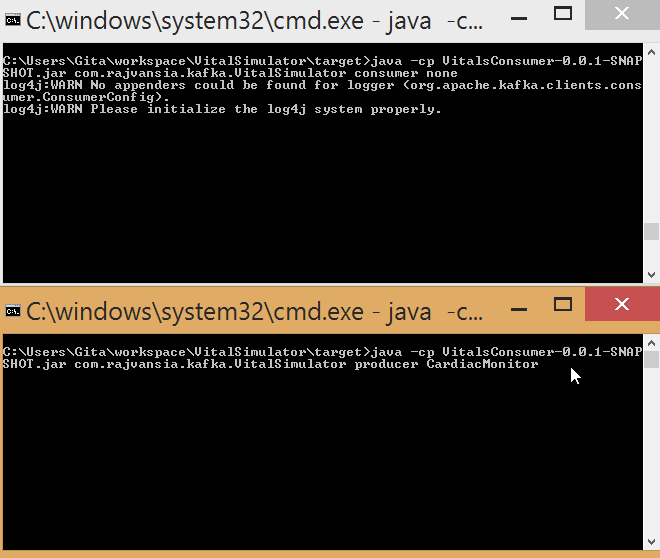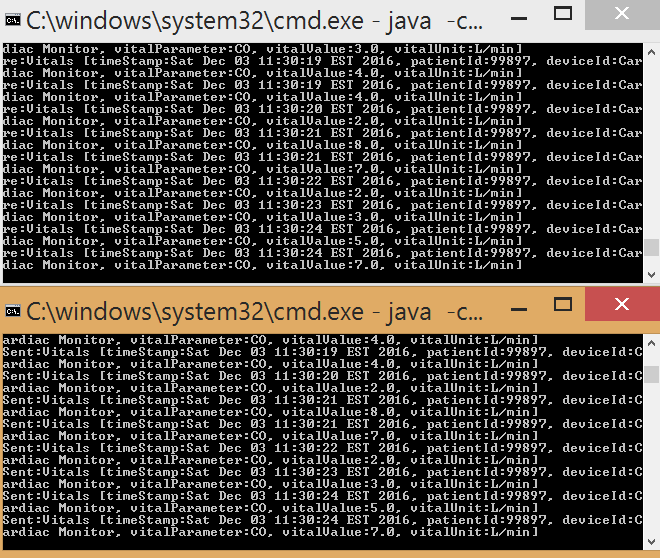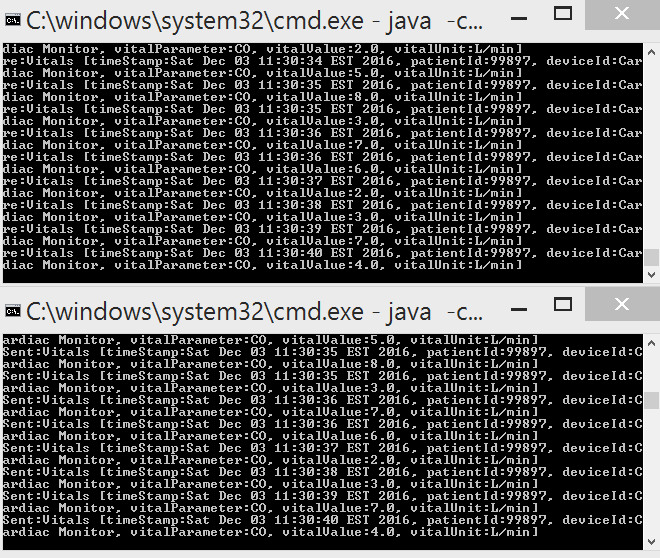
Create Multiple Vital Signs Producers
Now to see the power of Kafka we can spin up two more producers to simulate SpO2 and blood pressure. You will notice that these 3 simulated devices send data independently to the same topic, "vitals", to the data broker. Now if you look at your consumer app you can see how all the messages from the various devices are being consumed. This will allow us to analyze all of the patients vitals data generated from different sources.