Spark Kafka Streaming Setup
How to Run a Spark streaming Kafka Word Count example.
This will be a quick setup guide on how to run the Spark Kafka streaming example. The Kafka streaming example does not work right out of the box because Spark does not come with the org.apache.spark.streaming.kafka010 package. For this example we will be using Spark 2.0.2 and Kafka 10.1.0. This tutorial assumes that you have Spark and Kafka already installed. If you don’t have these installed you can follow the directions for Spark and Kafka. https://kafka.apache.org/quickstart
The word count example provided by Spark is a basic application that will count the occurrence of a word within a time window from a Kafka publish source. This demonstrates Spark Streaming’s ability to perform analysis on high throughput data. Spark will act as the subscriber and count all the words that come through from Kafka.
Setup a basic Kafka producer and consumer.
We will create a Kafka producer that we can simulate streaming data by entering text in the command line. The words that we type will then be published to our Spark consumer that will then take that stream of words we typed and perform a count operation on them.
First deploy your zookeeper server
zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties
Then deploy your Kafka broker
bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
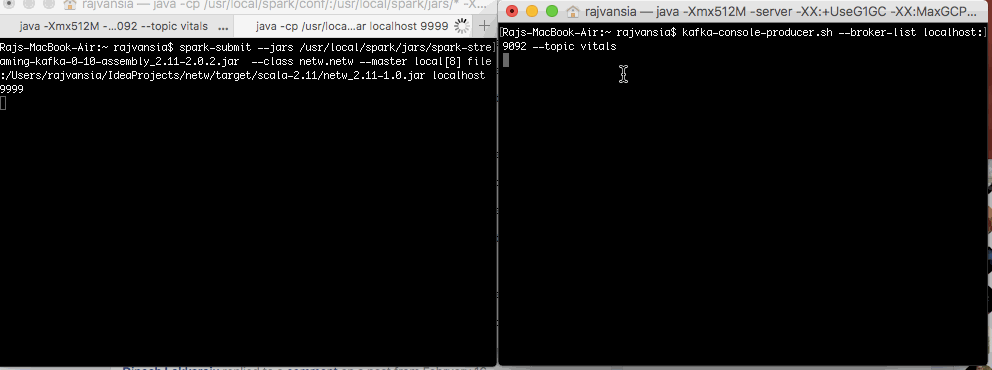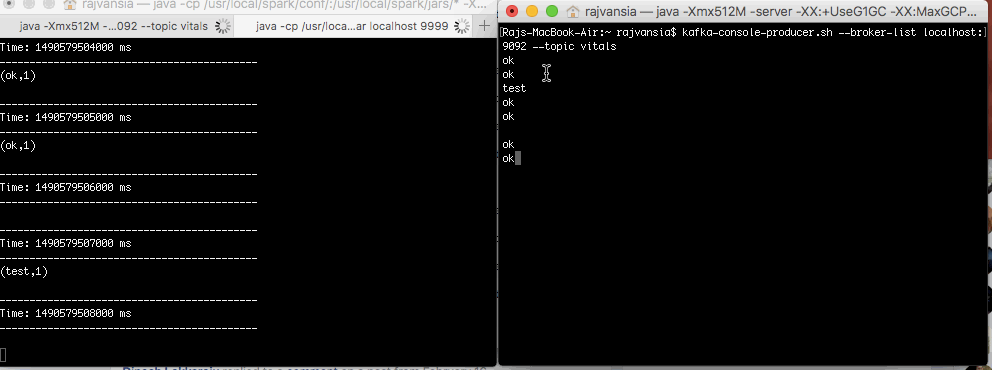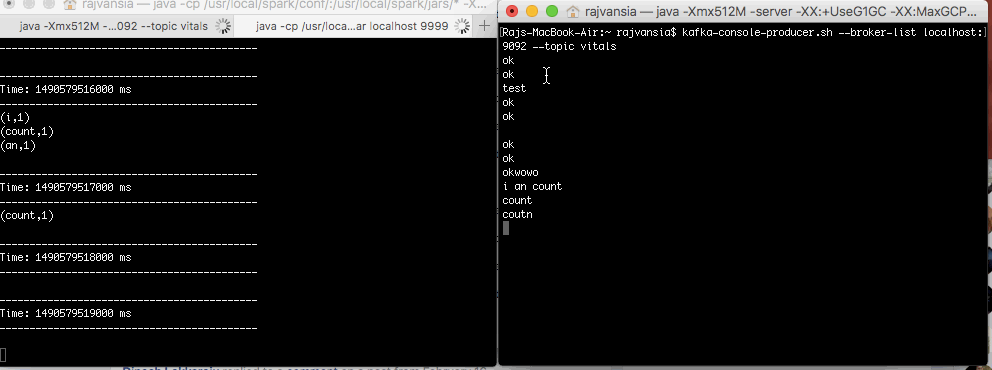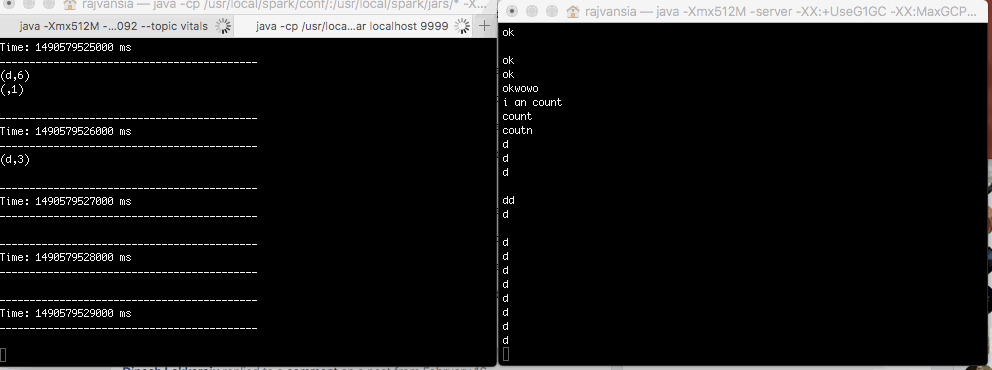
Now lets spin up our Kafka producer. The following command will create a Kafka producer where we define where our Kafka broker is running, which in our case is localhost 9092, we then define a topic for our producer. In this case we will use vitals. This topic is used by our consumers to subscribe to a topic and get data from any producer that is producing data under this topic.
bin/kafka-console-producer.sh --broker-list localt:9092 --topic vitals
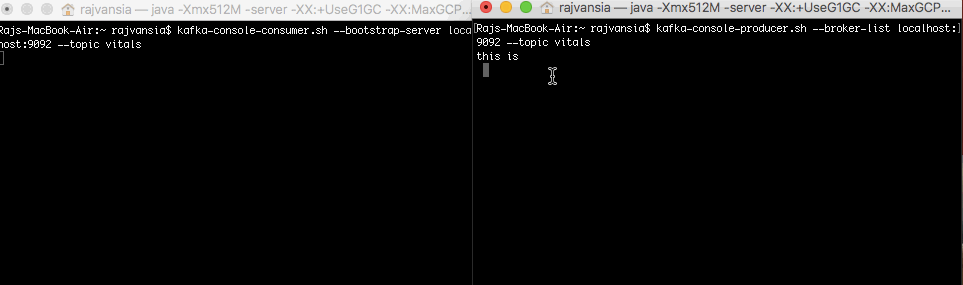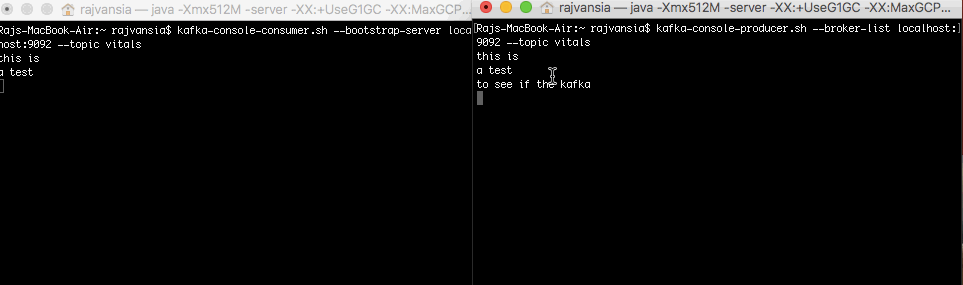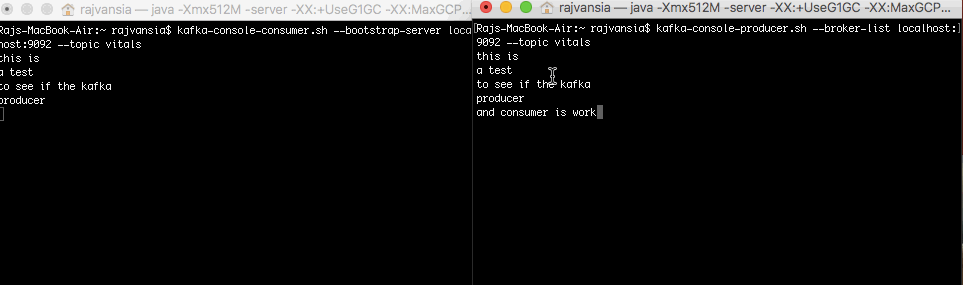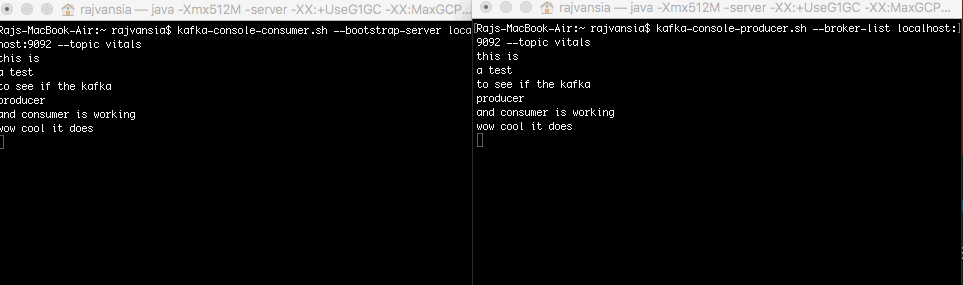
We can spin up a Kafka consumer to make sure that we can read the stream data from the producer before we try to use Spark. The consumer command is similar to the producer command, we need to make sure our topic is the same as our producer which is vitals.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic vitals
Now when you type anything in your producer terminal the words will display on your consumer that is subscribed to the topic. This shows that your consumer and producer setup is working. We will now use Spark to consume our Kafka stream.
2 ways to include the Spark Kafka Stearming package
In order to consume Kafka messages we need the Spark streaming Kafka utilities. You need to reference the class or else you will get a class not found error for Streaming.KafkaUtils. This is because Spark does not come with this class out of the box. There are two ways that we can accomplish this. One way is to submit the jar when you use spark submit. Secondly you can create an uber Jar with the streaming Kafka package.
Method 1 Define the Jar Dependency During Spark Submit
When you submit the Spark application you can reference the jars that are part of your dependencies. All you need to do is type — jars
spark-submit --jars /usr/local/spark/jars/spark-streaming-kafka-0-10-assembly_2.11-2.0.2.jar --class netw.netw --master local[8] file:/Users/rajvansia/IdeaProjects/nettarget/scala-2.11/netw_2.11-1.0.jar localhost 9999
You will now see your application start to run no longer getting a class not found error.
Method 2 Building an Uber Jar
If you do not feel like always referencing the class when you submit the job then you can build an uber jar that will include the Kafka streaming class. Now under your build.sbt Include the spark-streaming-kafka-0-10_2.11 package. Define the packages you already have within your environment which is Spark and Spark streaming as provided. This will prevent you from packaging dependancies you already have available. When we package our jar we will have the Kafka Streaming utils also included.
sbt assembly
We can submit our Spark application by defining the quorum and server. This will run your application and you will see the DSTREAM in your terminal every 10 seconds. If you type in your Kafka producer your Spark application will perform a count of words within that window time frame. Try copying a large amount of text, like this post, and paste it in Kafka and look at how fast Spark is able to perform the word count operation.
spark-submit --class netw.netw --master local[8] file:/Users/rajvansia/IdeaProjects/nettarget/scala-2.11/netw_2.11-1.0.jar localhost 9999
